

This is part four of nine of the ontology series. I encourage you to read the first three blogs to familiarize yourself with the concepts of ontologies and knowledge models, get a rudimentary understanding of how ontologies are utilized in AI, and increase interoperability.
We still start discussing the ‘semantic layer’ in future blogs. Common vocabularies are a crucial component of the semantic layer in data systems and AI applications that provide meaning and context to raw data. It is an intermediary between data storage and user interaction, translating complex data into understandable information using standardized terms and relationships. By leveraging standard vocabularies and ontologies, the semantic layer enables seamless data integration, enhances interoperability, and supports advanced querying and reasoning capabilities. This layer ensures data is consistently interpreted across different systems, facilitating accurate analysis and decision-making.
Ontologies define standardized terms that are consistently used across various systems and applications. By providing clear definitions for each term, ontologies ensure everyone (humans and machines) interprets these terms similarly, eliminating ambiguity and misunderstanding.
Confusion in Language:
We commonly see disparity in terminology in everyday language, leading to misunderstandings when discussing various topics and inaccurate representation when this terminology is executed in code. In human discussion, we can ascertain the implied intent of multiple words, but computers cannot utilize it without it being explicitly stated.
We can find examples of this throughout language that have diametrically opposed meanings, called contranyms, such as (pulled from Webster’s dictionary online):


My favorite contranym is cleave with probably the most opposed meanings:

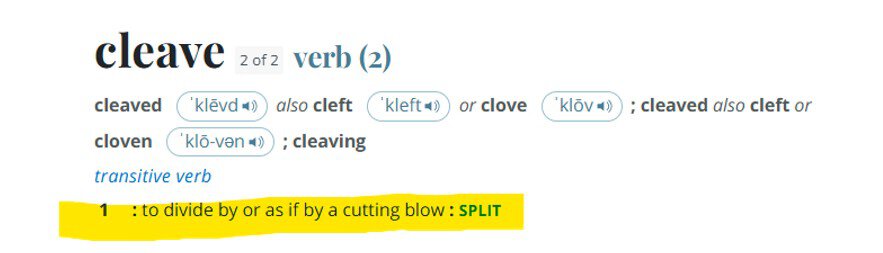
The above examples are extreme, but we can take more commonly used terms in code and see how they can lead to misunderstandings when executing against metadata.
Example
We will examine how standardizing our vocabulary can increase complexity and understandability across organizations. Let’s start with a simple example and increase complexity through standard methods.
In this example, two HR personnel work for a company we’ll call BabelFish Inc., with primarily remote employees. They have been tasked with creating a list of individuals who work for the company, their locations, and what they do for the company.
Spreadsheet Method:
The HR people at BabelFish Inc. don’t have access to any HR tools, so they have decided to create a spreadsheet and have come up with the following:
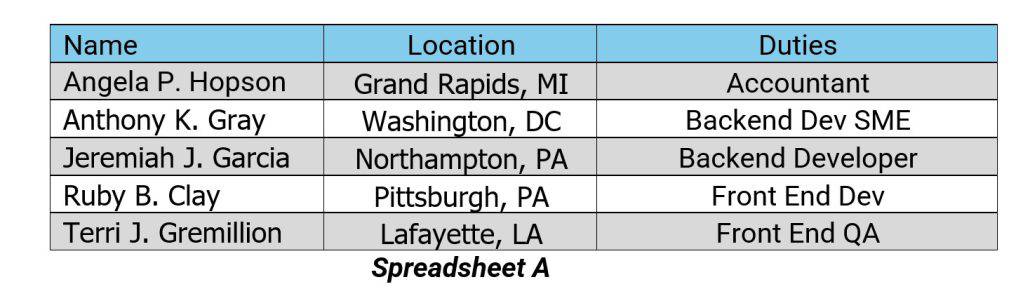
Spreadsheet A has the employees’ names, physical locations, and the work they do for BabelFish Inc. according to their hiring contracts.
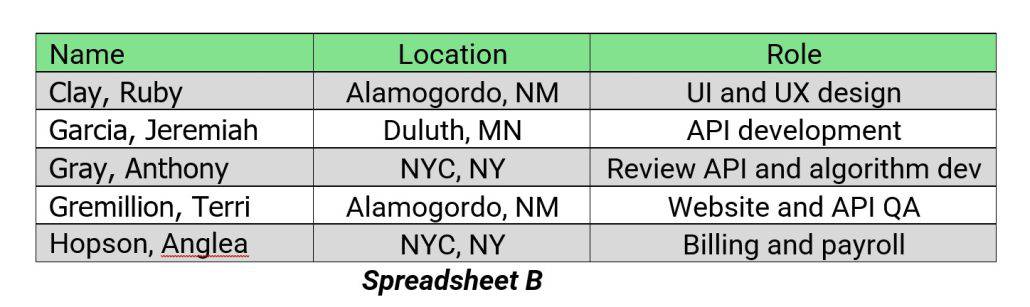
Spreadsheet B has the names of the employees, the locations of their customers that the employees support, and the work they do for that customer.
Each sheet provides value—but in different ways. Without common terminology, people are left to translate and standardize the data after the fact, which can lead to extensive time investment for large data sets. We can see the effects of not having standardized terminology: We cannot clearly understand what is being asked for, leading to data values not aligned across the domain (HR in this example).
OOP Method:
BabelFish Inc.’s CEO decided they need some simple HR tools, they have developed some code using OOP (object-orientated programming) to account for their employees and customers. The following code encompasses all of the columns in spreadsheets A and B and allows for typical data entry by the HR workers. With this, we can have a user interface that will enable HR to enter the details that have been captured in the spreadsheets and saved for future access, ensuring that the correct information is entered.
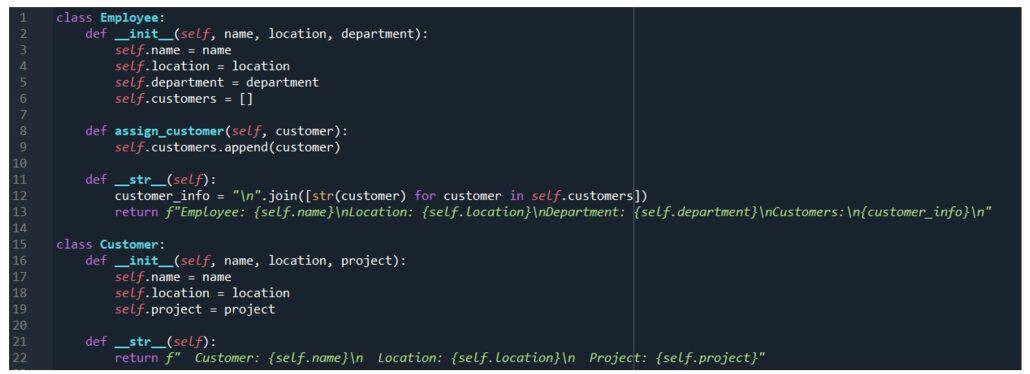
This method standardizes the input, but larger object-oriented projects can lead to issues with naming conventions and significant issues with interoperability across software.
Ontology Method:
For the last example, the CEO at BabelFish Inc. decides to standardize their semantics to assist with interoperability. They have utilized ontologies to standardize their lexicon, and there is a fundamental shift in how objects are treated, unlike OOP – ontologies do not require contained or globalized classes. OOP class management can become unwieldy when working on large development projects. Notice in the OOP example there are multiple naming conventions for name and location. One refers to the customer’s name, and the other the employee’s name. This can be overcome straightforwardly with ontologies. Below shows the taxonomy that is utilized in this example:
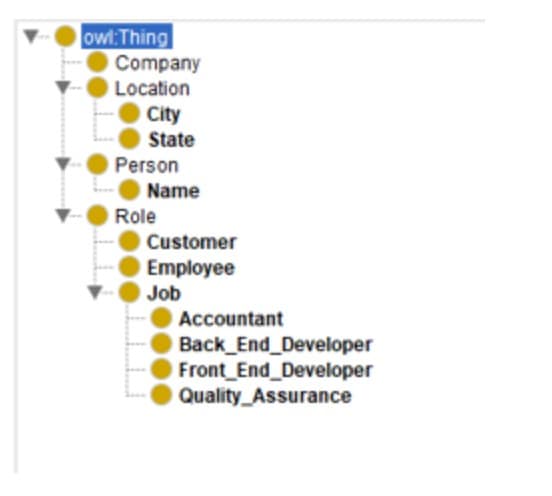
Each term is clearly defined within the owl file, and there is no distinction between customer and employee name or location as there is in the OOP example. The ontology can distinguish between customer and employee name, as shown below.
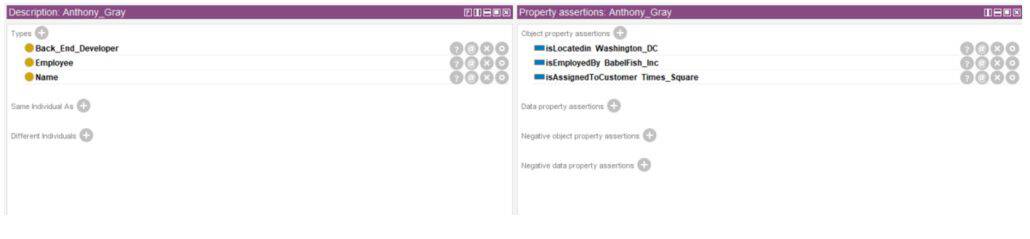
Above, we are looking at the employee named Anthony Gray, who has the role of an employee and is a backend developer. We can also see through the assertions that he is located in DC, employed at BabelFish, and assigned to the customer ‘Times Square.’ This is the first time we have seen a reference to a customer called ‘Times Square.’ Looking at this instance, we can see the following:
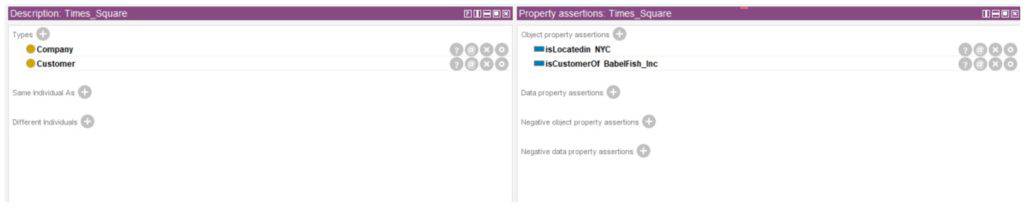
Times Square is a company located in NYC, and a customer of BabelFish Inc. Anthony supports this company with his backend development work. This ontology file can be uploaded in the integrated developing environment (IDE) python, java, cameo, etc. and provides the standardized framework, associations, inferences, and definitions that allow for interoperability across various platforms.
The Pay Off
Creating the ontology and ingesting it into development platforms `provides engineers and developers with the following, which exponentially increase production and removes guesswork:
- Hierarchical Structure Ontologies organize terms hierarchically, showing the relationships between broader and narrower concepts. This hierarchy helps users understand how different terms relate to each other and provides a clear structure for categorizing information.
- Relationship Definitions Beyond simply listing terms, ontologies define the relationships between those terms. This might include relationships such as “is a type of,” “is part of,” or “is related to.” By explicitly defining these relationships, ontologies enable systems to understand the context and connections between concepts.
- Semantic Consistency Ontologies ensure semantic consistency by providing a common framework for interpreting the meaning of terms. This consistency is crucial for data integration, as it allows systems to combine data from different sources without losing meaning or context.
- Facilitating Interoperability Ontologies facilitate interoperability between systems and applications by providing a shared vocabulary. When other systems use the same ontology, they can communicate and exchange data more effectively, as they share a common understanding of the terms and concepts involved.
In our work with ontologies, we have successfully implemented the definitions and taxonomy, allowing for standardized semantics from system engineers to data scientists to enterprise architects. This flat standardization enables all echelons of data practitioners to push and pull their products without investing time in naming conventions.
Adopting standard vocabularies often requires significant organizational change and buy-in from various stakeholders. Organizations may face resistance from employees accustomed to using their terminology or systems. Successful implementation requires careful planning, comprehensive training programs, and ongoing maintenance to ensure the vocabulary remains relevant and valuable.
Standard vocabularies are essential for organizations looking to maximize the value of their data and AI investments. Standardizing terms and definitions provides a solid foundation for data integration, AI development, and cross-functional collaboration. Organizations can build more efficient, accurate, and scalable data and AI systems that deliver lasting value by investing in standard vocabularies.
As we conclude this fourth installment of our ontology series, it’s clear that the journey toward adopting common vocabularies and ontologies is both transformative and essential for modern organizations. By embracing these standardized frameworks, companies can overcome the challenges of disparate terminology, ensuring clarity and consistency in data interpretation and communication. This shift not only enhances interoperability and streamlines operations but also empowers data practitioners at all levels to focus on innovation rather than semantics. As we look forward to exploring the semantic layer in upcoming discussions, the groundwork laid here highlights the profound impact that well-defined ontologies and vocabularies can have on maximizing the value of data and AI investments. The commitment to these standards may require organizational change and concerted effort, but the long-term benefits in efficiency, accuracy, and scalability make it a worthwhile endeavor.